Technical Documentation
Preambule
This subsection will explain precisely how the conversion process works. If you are reading this, I assume you are be familiar with XML technologies (i.e. ANT scripts, XSL-XSLT transformations and Hdoc format). I also recommend you to open my source files and read my comments.
Besides, the converter has been tested on recent ANT versions (> 1.7.0) only. It doesn't need any plugins (such as ANT-contrib, Java, Perl...) to work .
Converter working
This converter is using the following structure : a main ANT file (hdoc2Epub.ant), which handles routine tasks (zipping/unzipping archives, deleting temporary files), XSL-XSLT transformation or other ANT scripts calls.
This main ANT file is composed of several targets in order to make the building process easier to understand.
Basically, the default target (named "convert") calls every other targets or ANT scripts in a precise order via the <antcall> task.
Source Code contains 7 files :
hdoc2epub.ant
find_content.xsl
find_ressources.xsl
generateAntChapters.xsl
hdoc2xHTMLchap.xsl
generate_contentopf.xsl
generate_toc.xsl
Working process
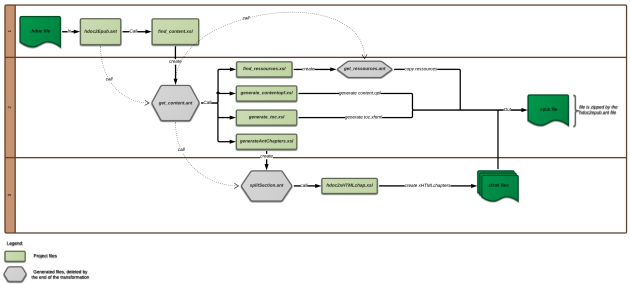
hdoc2epub.ant
The script need two arguments for work properly :
InputPath : Th input hdoc file path.
OutputPath : The desired output path for the created epub.
Make sur you have right in output folder and in the working directory.
In that order :
it unzips the hdoc file. The unzipped hdoc folder is named "hdoc".
it gets hdoc's "META-INF/container.xml" path and applies on it "find_content.xsl". The output file is named "get_content.ant"
it execute the get_content just generated
it compress the output folder in epub format and add mimetype file (mimetype file must be the first in the archive and encode options must be set)
It clean the working folder by deleting temporary files (get_content.ant, get ressources.ant, splitSection.ant, unzipped hdoc file, and result folder)
find_content.xsl
This file is used for generate get_content.ant wich permite to apply next transformations on file in the path found in the container.xml file. This file will be named "content file" in the following.
The ant do in this order :
Create the output directory named "result"
Copy the container.xml file contained in the archive in the output directory (note the hdoc container.xml file but an generic container.xml file for epub format)
Copy CSS file in the output directory
Call find_ressources.xsl file on the content file to create get_ressources.ant
Execute get_ressources.ant
Call generateAntChapters on the content file to create splitSection.ant
Execute splitSection.ant
Call generate_contentopf.xsl on the content file to generate content.opf file in the result directory.
Call generate_toc.xsl on the content file to generate toc.xhtml in the result directory
In this file, all xml transformations are called with the saxon9he processor given in the archive.
find _ressources.xsl
This file is used for generate get_ressources.ant wich permite to localize all external ressources in the input file and copy thoses files in the result/oebs directory sorted by type (but the precedent folder hierarchy is conserved) :
Images files, identified by an <img> tag, in the hdoc file are placed in result/oebs/images
Video files, identified by an <video> tag, are place in result/oebs/video
Audio files, identified by an <audio> tag, are place in result/oebs/audio
Others externales ressources, identified by an <object> tag, are place in result/oebs/res
For example if your input file have foo.png in a folder named "authors" and the ressource is referenced by an <ing> tag, it will be copied in result/oebs/images/authors/foo.png
generateAntChapters.xsl
The aim of this XSL is to generate an ant script named splitSection.ant for cuting the content file into multiple xHTML file, one for each chapter.
To do this, the choice has been to cut at each first-level <section> and to make one chapter for each.
The splitSection.ant generated contain multiple call to hdoc2xHTML.xsl on the content file with a different parameter for each call for identifying each section.
XSL transformations are called with saxon9he processor given in the archive.
generate_contentopf.xsl
The aim of this XSL is to build the content.opf file (located in result/oebs)
The main template (matching h:html elements) create the structure of the content.opf file and call other templates to fill needed informations :
<metadata> section : Template matching h:head get title and author informations.
<manifest> section :
First, it references the toc.xhtml file
Call Template matching h:body element, it will call serie of template (h:section, h:div, h:img, h:audio, h:video, h:object) to reference all external ressources, attribute them and id and a type.
Referencing all chapters contained in the oebs/text folder and attribute them a type and an id.
<spine> section references the table of content in first and then references chapters in oebs/text sorted by order.
generate_toc.xsl
This XSL premite to create anx xHTML fil witch contain the table of content of the epub. It references all chapters files in oebs/text folder.
Because, chapter file are already numbered and ordered at this step of the script, it is very easy to list all of them. It also get the chapter title to show it in the table of content.
hdoc2xHTMLchap.xsl
This file is called multiple time on the content file and receive a section identifier as parameter.
Working by followind these steps :
Create xHTML structure with head and body
Put in the head the title of the chapter, given by the /header/h1 of the section given as parameter.
Copy the identified section in the xHTML using an identity transformation for only changing namespace from hdoc to xHTML, updating ressources path to their new path, and removing processing instructions.
CSS
The CSS file is well commented to understand each properties.
Because of many readers doesn't respect standart, the output could be strange in certain reader, so read this page (http://wiki.mobileread.com/wiki/Device_Compatibility) to know what reader accept wat properties.
This CSS is a compromise to try to make the best result in all readers.